YOLOv8¶
摘要¶
Ultralytics YOLOv8 由 Ultralytics 开发,是一款尖端的、最先进的 (SOTA) 模型,它以之前 YOLO 版本的成功为基础,并引入了新功能和改进,以进一步提高性能和灵活性。YOLOv8 旨在快速、准确且易于使用,使其成为各种物体检测、图像分割和图像分类任务的绝佳选择。
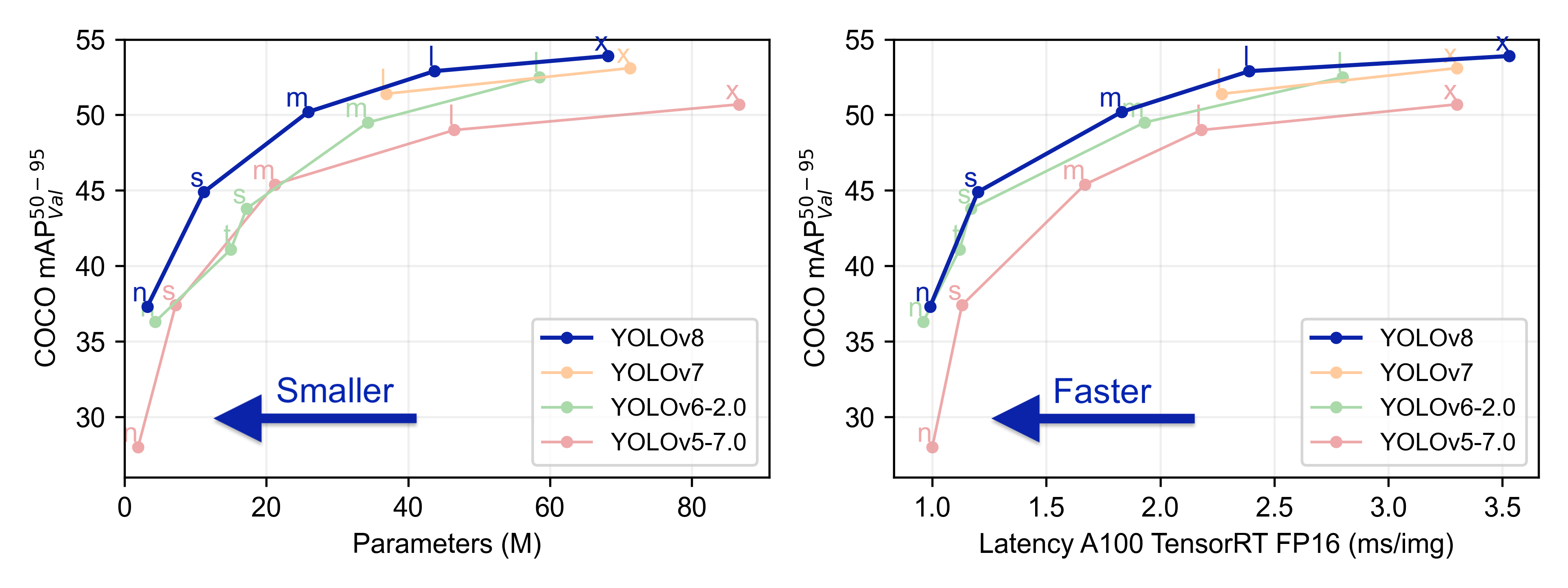
结果¶
图像检测¶
使用图模式在 Ascend 910(8p) 上测试的表现
| Name | Scale | BatchSize | ImageSize | Dataset | Box mAP (%) | Params | Recipe | Download |
|---|---|---|---|---|---|---|---|---|
| YOLOv8 | N | 16 * 8 | 640 | MS COCO 2017 | 37.2 | 3.2M | yaml | weights |
| YOLOv8 | S | 16 * 8 | 640 | MS COCO 2017 | 44.6 | 11.2M | yaml | weights |
| YOLOv8 | M | 16 * 8 | 640 | MS COCO 2017 | 50.5 | 25.9M | yaml | weights |
| YOLOv8 | L | 16 * 8 | 640 | MS COCO 2017 | 52.8 | 43.7M | yaml | weights |
| YOLOv8 | X | 16 * 8 | 640 | MS COCO 2017 | 53.7 | 68.2M | yaml | weights |
在Ascend 910*(8p)上测试的表现
| Name | Scale | BatchSize | ImageSize | Dataset | Box mAP (%) | ms/step | Params | Recipe | Download |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv8 | N | 16 * 8 | 640 | MS COCO 2017 | 37.3 | 373.55 | 3.2M | yaml | weights |
| YOLOv8 | S | 16 * 8 | 640 | MS COCO 2017 | 44.7 | 365.53 | 11.2M | yaml | weights |
图像分割¶
使用图模式在 Ascend 910(8p) 上测试的表现
| Name | Scale | BatchSize | ImageSize | Dataset | Box mAP (%) | Mask mAP (%) | Params | Recipe | Download |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv8-seg | X | 16 * 8 | 640 | MS COCO 2017 | 52.5 | 42.9 | 71.8M | yaml | weights |
说明¶
- Box mAP:验证集上测试出的准确度。
- 我们参考了常用的第三方 YOLOV8 重现了P5(大目标)系列模型。
快速入门¶
详情请参阅 MindYOLO 中的 快速入门。
训练¶
- 分布式训练¶
使用预置的训练配方可以轻松重现报告的结果。如需在多台Ascend 910设备上进行分布式训练,请运行
# 在多台Ascend设备上进行分布式训练
msrun --worker_num=8 --local_worker_num=8 --bind_core=True --log_dir=./yolov8_log python train.py --config ./configs/yolov8/yolov8n.yaml --device_target Ascend --is_parallel True
注意: 更多关于msrun配置的信息,请参考这里。
有关所有超参数的详细说明,请参阅config.py。
注意: 由于全局batch size(batch_size x 设备数)是一个重要的超参数,建议保持全局batch size不变进行复制,或者将学习率线性调整为新的全局batch size。
- 单卡训练¶
如果您想在较小的数据集上训练或微调模型而不进行分布式训练,请运行:
# 在 CPU/Ascend 设备上进行单卡训练
python train.py --config ./configs/yolov8/yolov8n.yaml --device_target Ascend
验证和测试¶
要验证训练模型的准确性,您可以使用 test.py 并使用 --weight 传入权重路径。
python test.py --config ./configs/yolov8/yolov8n.yaml --device_target Ascend --weight /PATH/TO/WEIGHT.ckpt
部署¶
详见 部署。
引用¶
[1] Jocher Glenn. Ultralytics YOLOv8. https://github.com/ultralytics/ultralytics, 2023.