YOLOX¶
Abstract¶
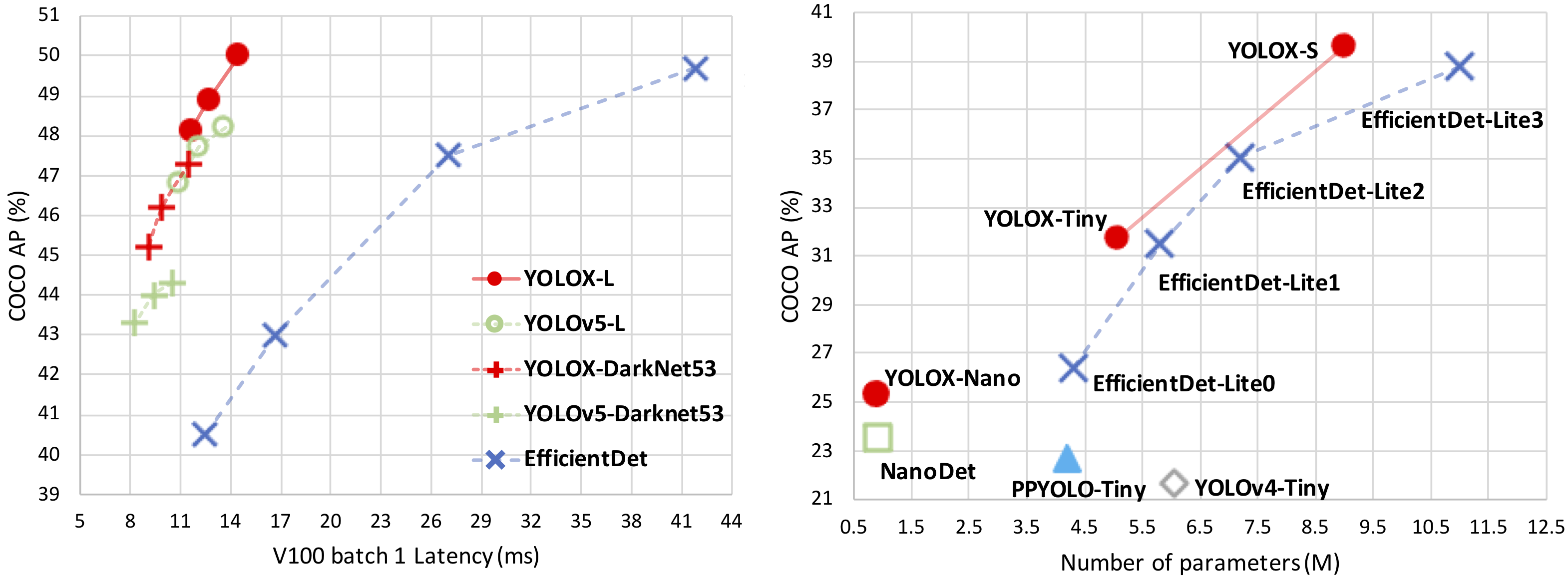
YOLOX is a new high-performance detector with some experienced improvements to YOLO series. We switch the YOLO detector to an anchor-free manner and conduct other advanced detection techniques, i.e., a decoupled head and the leading label assignment strategy SimOTA to achieve state-of-the-art results across a large scale range of models: For YOLO-Nano with only 0.91M parameters and 1.08G FLOPs, we get 25.3% AP on COCO, surpassing NanoDet by 1.8% AP; for YOLOv3, one of the most widely used detectors in industry, we boost it to 47.3% AP on COCO, outperforming the current best practice by 3.0% AP; for YOLOX-L with roughly the same amount of parameters as YOLOv4-CSP, YOLOv5-L, we achieve 50.0% AP on COCO at a speed of 68.9 FPS on Tesla V100, exceeding YOLOv5-L by 1.8% AP. Further, we won the 1st Place on Streaming Perception Challenge (Workshop on Autonomous Driving at CVPR 2021) using a single YOLOX-L model.
Results¶
performance tested on Ascend 910(8p) with graph mode
| Name | Scale | BatchSize | ImageSize | Dataset | Box mAP (%) | Params | Recipe | Download |
|---|---|---|---|---|---|---|---|---|
| YOLOX | N | 8 * 8 | 416 | MS COCO 2017 | 24.1 | 0.9M | yaml | weights |
| YOLOX | Tiny | 8 * 8 | 416 | MS COCO 2017 | 33.3 | 5.1M | yaml | weights |
| YOLOX | S | 8 * 8 | 640 | MS COCO 2017 | 40.7 | 9.0M | yaml | weights |
| YOLOX | M | 8 * 8 | 640 | MS COCO 2017 | 46.7 | 25.3M | yaml | weights |
| YOLOX | L | 8 * 8 | 640 | MS COCO 2017 | 49.2 | 54.2M | yaml | weights |
| YOLOX | X | 8 * 8 | 640 | MS COCO 2017 | 51.6 | 99.1M | yaml | weights |
| YOLOX | Darknet53 | 8 * 8 | 640 | MS COCO 2017 | 47.7 | 63.7M | yaml | weights |
performance tested on Ascend 910*(8p)
| Name | Scale | BatchSize | ImageSize | Dataset | Box mAP (%) | ms/step | Params | Recipe | Download |
|---|---|---|---|---|---|---|---|---|---|
| YOLOX | S | 8 * 8 | 640 | MS COCO 2017 | 41.0 | 242.15 | 9.0M | yaml | weights |
Notes¶
- Box mAP: Accuracy reported on the validation set.
- We refer to the official YOLOX to reproduce the results.
Quick Start¶
Please refer to the QUICK START in MindYOLO for details.
Training¶
- Distributed Training¶
It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple Ascend 910 devices, please run
# distributed training on multiple Ascend devices
msrun --worker_num=8 --local_worker_num=8 --bind_core=True --log_dir=./yolox_log python train.py --config ./configs/yolox/yolox-s.yaml --device_target Ascend --is_parallel True
Note: For more information about msrun configuration, please refer to here.
For detailed illustration of all hyper-parameters, please refer to config.py.
Note: As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep the global batch size unchanged for reproduction.
- Standalone Training¶
If you want to train or finetune the model on a smaller dataset without distributed training, please firstly run:
# standalone 1st stage training on a CPU/Ascend device
python train.py --config ./configs/yolox/yolox-s.yaml --device_target Ascend
Validation and Test¶
To validate the accuracy of the trained model, you can use test.py and parse the checkpoint path with --weight.
python test.py --config ./configs/yolox/yolox-s.yaml --device_target Ascend --weight /PATH/TO/WEIGHT.ckpt
Deployment¶
See here.
References¶
[1] Zheng Ge. YOLOX: Exceeding YOLO Series in 2021. https://arxiv.org/abs/2107.08430, 2021.